|
Glottal-flow PCA model
By considering the entire shape of individual glottal pulses extracted from acoustic recordings, rather than imposing pre-defined mathematical constraints on possible waveshapes, we derived a more holistic model that parameterizes glottal flow across a wide range of voice qualities. |
| BACKGROUND |
Human vocal communication is rarely limited to the verbal or linguistic message: listeners can infer a speaker's attitude, state of health, mood, emotion, and other characteristics, from the "tone of voice" — a popular term for what speech scientists call prosody (pitch, loudness, duration) and voice quality (laryngeal, supralaryngeal). Among these paralinguistic attributes, the laryngeal component of voice quality is of particular interest, as it is least influenced by the verbal content (at least in languages such as English, that do not use voice quality for linguistic contrast). Acoustically, what we hear as a person's laryngeal voice quality is determined by temporal and spectral characteristics of the glottal flow waveform — the volume velocity of airflow that passes through the aperture between the vocal folds (glottis). During voiced sounds, the folds undergo self-sustaining oscillations, rapidly opening and closing to let through a series of pulses. The shape of these pulses, and the degree of accompanying air-turbulence, are determined by the speaker's physiological settings: subglottal air-pressure (exerted from the lungs) and laryngeal muscle forces (longitudinal tension, medial compression, adductive tension). |
| PULSE-SHAPE MODELLING |
Various parametric models of the glottal flow pulse shape have been proposed for both analysis and synthesis of the human voice; usually, these are mathematical models that stylize or approximate real pulses, designed by researchers to capture and control what are believed to be their most salient features (e.g., Rosenberg, 1971; Fant et al., 1985; Klatt & Klatt, 1990; Veldhuis, 1998). We pioneered an alternative, data-driven approach, where the salient features of glottal flow pulse-shapes are determined by statistical analysis of pulses measured in a range of voice qualities. In this project, audio recordings made by Professor John Laver to demonstrate a wide range of voice qualities (Laver, 1980) were analyzed by inverse filtering to extract examples of glottal pulses in each of 13 different voice qualities (including for example modal, falsetto, creak, breathy voice, and tense voice). To facilitate statistical analysis, each glottal pulse was resampled at a constant number of equal-length intervals. All the resampled pulse shapes were then subjected to principal components analysis (PCA). |
| RESULTS |
Statistical analysis succeeded in reducing a high-dimensional representation of the glottal pulse shape (represented by 30 samples in each of time and amplitude, i.e. 60 parameters), down to just 4 principal components that together accounted for 92% of the total variance. Remarkably, these 4 basis functions which were derived entirely from analysis of measured data, also lended themselves easily to interpretation (Mokhtari et al., 2003; Mokhtari, 2003), as shown in this figure: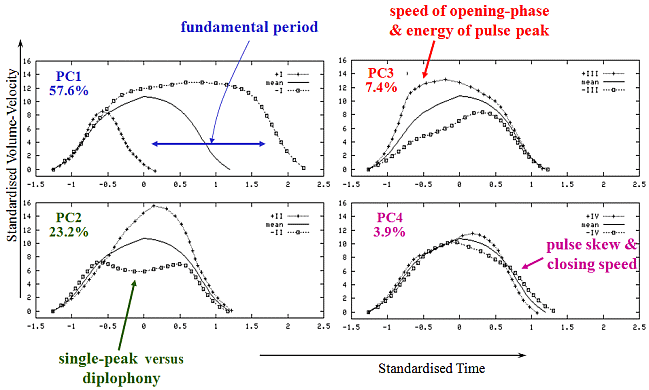
Our model was subsequently used to demonstrate the feasibility of automatically converting the voice quality of a spoken sentence (Mokhtari, 2003; Mokhtari et al., 2004). The applicability of our model was also significantly extended by Pfitzinger (2008), who applied PCA to 92167 manually segmented glottal flow waveforms of 44 speakers, to examine both segmental variations and supra-segmental contours of voice quality. |
| LIMITATIONS |
It is well known that in general, the factors yielded by PCA can be sensitive to the exact nature and balance of the underlying data. While Laver's (1980) recordings included a balanced variety of laryngeal voice qualities, it was restricted to only one person's voice, and therefore the 4 PCs shown above should by no means be considered a fixed and rigid model. Mokhtari et al. (2004) also analyzed only one (female Japanese) speaker's voice, but with a much larger number of glottal pulses extracted automatically from at least 100 minutes of continuous speech. Pfitzinger's (2008) analysis of 44 people's voices then significantly extended our initial studies to include males and females as well as two languages (English and German). The resulting PCs showed some similarities as well as marked differences compared with the factors shown above. Depending on what type of model one wishes to generate, with such large amounts of data it may be necessary to control for variations across speakers, languages, and other sources of variability. Another potential limitation of our initial study is that Laver's (1980) recordings were made on analogue tape, which may have introduced phase nonlinearities that would have affected the shape of the time-domain waveform. This may be why the pulses extracted from that data often lacked a well-defined closed-phase portion of the glottal cycle. Nevertheless, such limitations do not undermine the validity of our modelling approach, which has indeed been adopted in subsequent studies as described below. |
| IMPACT |
We are very pleased to see that the holistic glottal waveshape modelling approach that we introduced at the Voice Quality Workshop in Geneva in 2003, has subsequently proved useful to a number of other researchers involved in laryngeal voice quality analysis and synthesis. For example:
|
| REFERENCES (chronological) |
A. E. Rosenberg (1971) Effect of glottal pulse shape on the quality of natural vowels J. Acoust. Soc. Am., 49(2), 583-590. J. Laver (1980) The phonetic description of voice quality Cambridge University Press, Cambridge. G. Fant, J. Liljencrants & Q. Lin (1985) A four-parameter model of glottal flow STL-QPSR (KTH), 4, 1-13. D. H. Klatt & L. C. Klatt (1990) Analysis, synthesis, and perception of voice quality variations among female and male talkers J. Acoust. Soc. Am., 87(2), 820-857. R. Veldhuis (1998) A computationally efficient alternative for the Liljencrants-Fant model and its perceptual evaluation J. Acoust. Soc. Am., 103(1), 566-571. P. Mokhtari, H. R. Pfitzinger & C. T. Ishi (2003) Principal components of glottal waveforms: towards parameterisation and manipulation of laryngeal voice-quality in Proc. ISCA Tutorial & Research Workshop "Voice Quality: Functions, Analysis and Synthesis" (Voqual'03), Geneva, Switzerland, 133-138. P. Mokhtari (2003) Parameterisation and control of laryngeal voice quality by principal components of glottal waveforms J. Phonetic Society of Japan, 7(3), 40-54. P. Mokhtari, H. Pfitzinger, C. T. Ishi & N. Campbell (2004) Laryngeal voice quality conversion by glottal waveshape PCA in Proc. Spring Meeting Acoust. Soc. Japan, Atsugi, Japan, Paper 2-P-6, 341-342. J. Kreiman, B. R. Gerratt & N. Antonanzas-Barroso (2007) Measures of glottal source spectrum J. Speech, Language, and Hearing Research, 50, 595-610. H. Pfitzinger (2008) Segmental effects on the prosody of voice quality in Proc. Acoustics-08, Paris, France, 5 pp. M. R. P. Thomas, J. Gudnason & P. A. Naylor (2009) Data-driven voice source waveform modelling in Proc. IEEE-ICASSP, Taipei, Taiwan, 3965-3968. J. Gudnason, M. R. P. Thomas, P. A. Naylor & D. P. W. Ellis (2009) Voice source waveform analysis and synthesis using principal component analysis and Gaussian mixture modelling in Proc. Interspeech, Brighton, UK, 4 pp. C. Mooshammer (2010) Acoustic and laryngographic measures of the laryngeal reflexes of linguistic prominence and vocal effort in German J. Acoust. Soc. Am., 127(2), 1047-1058. J. Gudnason, M. R. P. Thomas, D. P. W. Ellis & P. A. Naylor (2012) Data-driven voice source waveform analysis and synthesis Speech Communication, 54, 199-211. G. Chen, J. Kreiman, B. R. Gerratt, J. Neubauer, Y.-L. Shue & A. Alwan (2013) Development of a glottal area index that integrates glottal gap size and open quotient J. Acoust. Soc. Am., 133(3), 1656-1666. J. Kuang & P. Keating (2014) Vocal fold vibratory patterns in tense versus lax phonation contrasts J. Acoust. Soc. Am., 136(5), 2784-2797. |
| Copyright ©Parham Mokhtari 2000-2024 |
Updated: 22 March 2022 |