Research Project
Auditory Telepresence Robot "TeleHead"
The aim of this project is to develop an acoustical telepresence robot that can reproduce the 3D sound environment of
a remote place at a listener's ears as if the listener is in the remote place. Our idea is to use a steerable dummy head,
named TeleHead, to track a listener's head movement in real time.
Traditional virtual 3-D sound reproduction technologies are based on signal processing technologies, which require
precise measurements of head-related transfer functions (hrTFs) of listeners as well as complex and numerous
computations. In addition, the technologies subsume that the listening position is only one point and that a listener's
head and body remain stationary. In contrast, the TeleHead requires neither precise hrTFs nor complex or numerous computations.
It reproduces real 3-D sound with moving-head and moving-sound-source conditions. TeleHead uses the principle that
the brain computes the sound source position in a 3-D space based on binaural sound information and head movement information.
A user-like dummy head as a physical entity 'computes' accurate hrTFs of the user in real time. Reproducing a listener's
head movements provides the right dynamic binaural information that is crucial for reproducing 3-D sound. Moreover,
it reduces mismatches between motion and acoustic information for the brain.
We have been investigating effects of head movement on sound localization, effects of dummy head shapes on sound localization,
headphones/earphones suitable for binaural systems, and effects of head movement in hrTF measuremens.
We have also built a dynamic virtual auditory display system running on a Windows XP based PC system
to compar-ee sound localization performances with the TeleHead system.
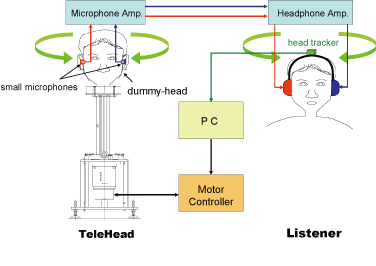
Schematics of a tele-robotics auditory terepresence system, TeleHead
-
Makoto Otani, Tatsuya Hirahara, Shiro Ise, "Numerical study on source-distance dependency of head-related transfer functions,"
J. Acoust. Soc. Am. 125(5), 3253-3261 (2009)
(abstract)
-
Makoto Otani, Tatsuya Hirahara, "Auditory Artifacts due to Switching Head-Related Transfer Functions of a Dynamic Virtual Auditory Display,"
IEICE Trans on Fundamentals of Electronics, Communications and Computer Sciences E91-A(6), 1320-1328 (2008)
(abstract)
-
Iwaki Toshima, Shigeaki Aoki, Tatsuya Hirahara, "Sound Localization Using an Acoustical Telepresence Robot: TeleHead II,"
Presence 17(4), 365-375 (2008)
(abstract)
-
Hiroshi Kawano, Hideyuki Ando, Tatsuya Hirahara, Cheolho Yun, Sadayuki Ueha,
"Methods for Applying a Multi-DOF Ultrasonic Servo Motor to an Auditory Tele-existence robot "TeleHead","
IEEE Trans. on Robotics 21(5), 790-800 (2005)
(abstract)
-
Iwaki Toshima, Hishashi Uematsu, Tatsuya Hirahara,"A steerable dummy head that tracks three-dimensional head movement: TeleHead,"
Acoustical Science and Technology 24(5), 327-329 (2003)
(J-STAGE)
Silent-Speech Technology
for Voice Disordered People
This project is intended to develop a technology that enables people with voice disorders to communicate using speech.
When vocal cord function is degraded or even lost as a result of laryngectomy, we lose our voice. Even when we lose voice capability,
weak vocal tract resonance sounds can be generated with weak air flows from the trachea or with a weak vibrator as long as
the articulators remain functional.
This weak vocal tract resonance sound, which is named non-audible murmur (NAM),
is detectable as a body-conducted voice sound by a special sensor attached to the neck. We have revealed the NAM generation mechanism,
the NAM propagation characteristics, through body and acoustical characteristics of the NAM sensor.
Furthermore, we have developed a transformed artificial speech system that transforms the NAM signal into a readable whispered voice sound.
Using the system, people with voice disorders are able to use revived speech communication.
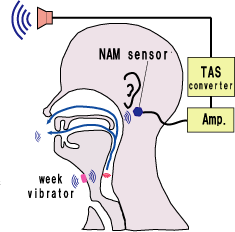
A speech aid system using NAM signal
We have revealed the NAM production mechanism, the NAM propagation characteristics through body, and acoustical characteristics of NAM sensors.
Furthermore, we have developed a voice transformation subsystem that transforms the NAM signal into readable whispered voices.
Waveform and spectrogram of NAM signals recorded for a male talker (left) and a female talker (right) with a soft-silicone-type NAM microphone.
The Japanese sentence spoken is "arajuru geNdZitsuo [subete]"; its meaning is "all the reality".
Waveform and spectrogram of NAM signals recorded simultaneously with
a soft-silicone-type NAM microphone (left) and a newly developed urethane-elastomer-duplex-type NAM microphone (right).
The Japanese sentence spoken is "youkoso tojama keNritsu daigaku e"; the meaning is "Welcome to Toyama Prefectural University".
The voice transformation system transforms NAM signals driven by a vibrator (left) into readable whispered voices (left).
The utterance is
The Japanese sentence spoken is "demo hoNtouni sounaNdesu"; the meaning is "but it is actually so".
This project was supprted by Strategic Information and
Communications R & D Promotion Programme (SCOPE) of the Ministry of Internal Affairs and Communications Japan from June 2005 to March 2008.
We have conducted this project with Shikano Lab. NAIST
and Nara Medical University.
-
Tatsuya Hirahara, Makoto Otani, Shota Shimizu,Tomoki Toda, Keigo Nakamura, Yoshitaka Nakajima, Kiyohiro Shikano,
"Silent-speech enhancement using body-conducted vocal-tract resonance signals,"
Speech Communication 52(4), 301-313,(2010)
(abstract)
-
Shota Shimizu, Makoto Otani, Tatsuya Hirahara,"Frequency characteristics of several non-audible murmur (NAM) microphones,"
Acoustical Science and Technology 30(2), 139-142,(2009)
(PDF 153kB)
-
Makoto Otani, Tatsuya Hirahara, Shota Shimizu, Seiji Adachi,"Numerical simulation of transfer and attenuation characteristics of soft-tissue conducted sound originating from vocal tract,"
Applied Acoustics 70(3), 469-472,(2009)
(abstract)
-
Makoto Otani, Shota Shimizu, Tatsuya Hirahara,"Vocal tract shape of non-audible murmur production,"
Acoustical Science and Technology 29(2), 195-198,(2008)
(PDF 193kB)
Investigation of Earphones and Headphones
The aim of this project is to know physical characteristics of earphones and headphones used in psychoacoustical experiments. We have measured actual-ear response, the IEC711 or IEC317 coupler response,
phase rotation and group delay, sound attenuation, acoustic crosstalk, and harmonic distortion characteristics of the TDH39 (Telephonics), DT48 (Bayer Dynamics), HD250 Linear II (Sennheiser), HD414 Classic (Sennheiser), HDA200 (Sennheiser),
SR-Lambda Professional (STAX), K-1000 (AKG), ATH-CK2 (Audiotechnica), E4C (Shure), ER4B (Etymotic Research), MDR-EX90SL (SONY), SR-001 MK2 (STAX), MX500 (Sennheiser) and TriPort IE (Bose).
The results indicate that the actual-ear response of all earphones and headphones does not necessarily coincide with the coupler response. The actual-ear response below 300 Hz is often lower than the coupler response because of acoustic leaks.
The actual-ear response at mid frequency range fits with the coupler response, the actual-ear response between 6 to 10 kHz is always lower by at least 6 dB than the IEC711 coupler response.
The actual-ear response at high frequency range over 10 kHz does not fits with the coupler response, as the IEC coupler does not garantee that frequency range.
It is highly recommended that earphones and headphones be calibrated before one conducts acoustical experiments, keeping in mind the discrepancy between actual-ear and artificial-ear responses.

Various types of earphones/headphones
-
Tatsuya Hirahara, "Discrepancies between actual-ear and artificial-ear responses,"
Proc. 20th International Congress on Acoustics, pp.474.1-474.4,
(2010 Sydney). (PDF 190kB)
-
Tatsuya Hirahara, Hiroaki Aoyama, Makoto Otani, "Physical characteristics of earphones and issues of IEC60711 coupler,"
Journal of the Acoustical Society of Japan 66(2), 45-55, (2010).
(PDF 1194 kB) (in Japanese)
-
Tatsuya Hirahara: "Physical characteristics of headphones used in psychophysical experiments,"
Acoustical Science and Technology 25(4), 276-285 (2004).
(PDF 532KB)
Acoustic Characteristics of Japanese Vowels
The aim of this project is to build a large database of Japanese vowels and to clarify their acoustic characteristics.
The major acoustic correlates of vowel quality are formant frequencies that reflect vocal tract resonances. Chiba and Kajiyama (1942)
carried out pioneering work on vowels. Since their work, dozens of studies of Japanese vowels have been done. Notwithstanding,
no systematic investigation of the acoustic characteristics of Japanese vowels exists except for those of Kasuya et al. (1968)
and Okuda et al. (2002). The present study therefore clarifies the acoustic characteristics of Japanese vowels based on
a large-scale database in which the uttering conditions are varied systematically. We have continued building a Japanese vowel
database that is compar-eable to that of American English vowels built by Hillenbrand et al. (1995).
This Japanese vowel database is useful for studies of acoustic phonetics and for speech engineering.
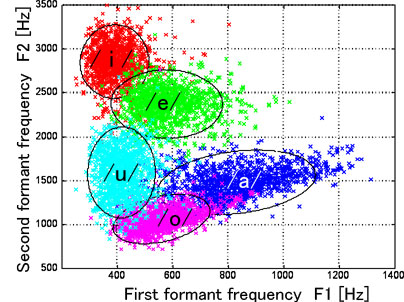
F1-F2 distribution of Japanese vowels (adult male talkers)
-
Tatsuya Hirahara, Reiko Akahane-Yamada,"Acoustic characteristics of Japanese vowels,"
Proc. 18th International Congress on Acoustics, Kyoto, IV-3287-3290 (2004)
(PDF 357kB)





